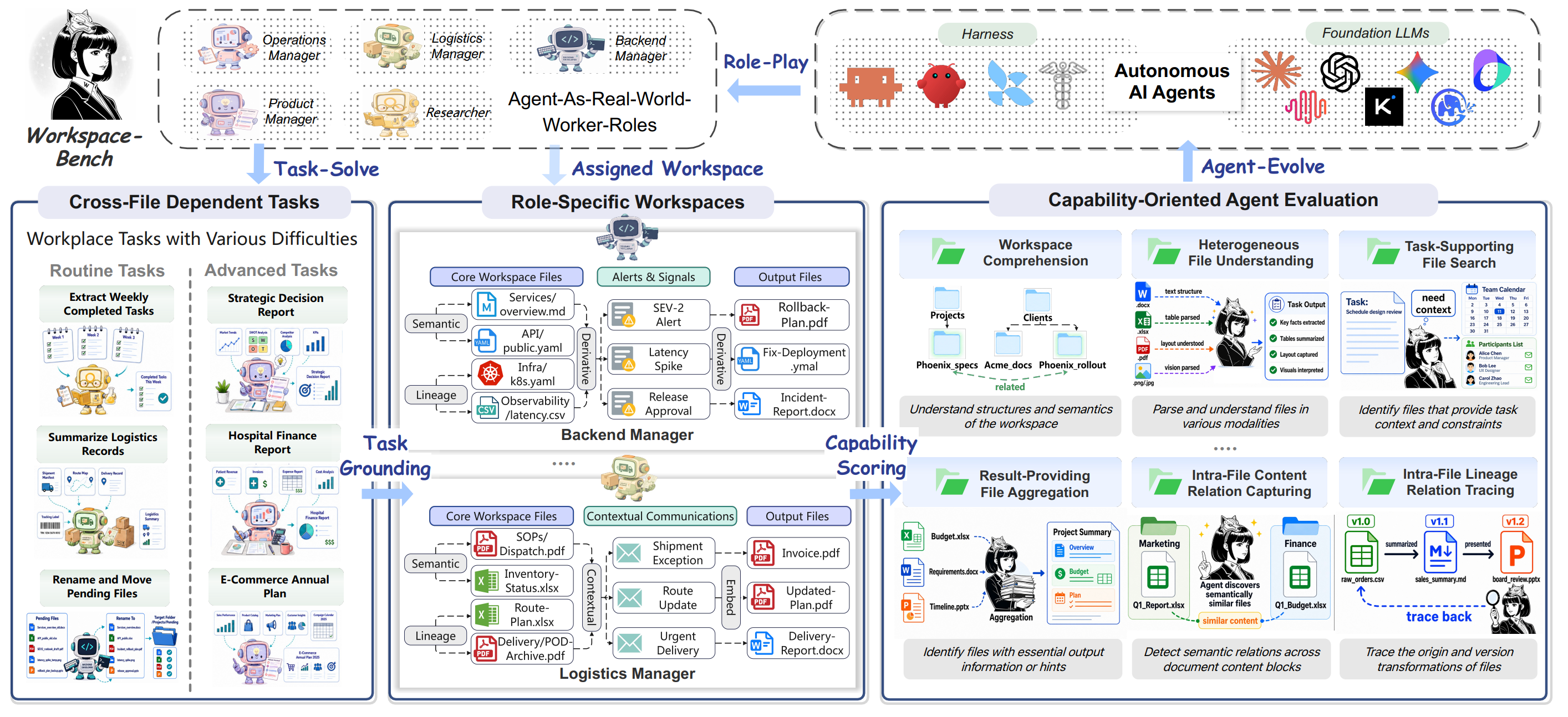
Workspace Exploration
Navigating deeply nested directory structures and identifying relevant files from noisy candidates.
Task-Supporting Files Utilization
Finding files that provide essential context, references, and domain knowledge needed to complete a task.
Result-Providing Files Utilization
Aggregating result files that contain required outputs, formats, and baseline information.
Content Relations Understanding
Tracing explicit references, semantic connections, and contextual links between related documents.
Semantic Heterogeneous File Understanding
Connecting information across diverse modalities including documents, spreadsheets, presentations, and code.
Lineage Tracing
Understanding file versions, revisions, and derivation relationships (e.g., report_v1, report_final).